Data Science (DS), Data Mining (DM) and Machine Learning (ML)
Data are normally facts, texts, or numbers processed by the computing devices. Typical sources of data may include databases, flat files, on-line transaction records, spreadsheets, or any other information repositories. In earlier days of information processing, researchers used to follow manual extraction of patterns from data using mathematical and statistical methods. The growth, ubiquity, and emerging power of computer technology have sensationally increased data collection, storage, and management capability. Since real-world databases have developed in size and complexity, direct practical data analysis has increasingly been improved with unanticipated, computerized data processing.
The plenty of data, combined with the requirement for potential software tools for data analysis, has been designated as a “data-rich but information-poor condition”. The rapid-growing, vast amount of data, gathered and retained in large and numerous data sources, has far exceeded the human capability for understanding without powerful tools. The widening gap between data and information always requires a systematic development of data processing tools. As a result, technical terms like data science, data mining and machine learning came into existence.
Data Science (DS)
It is a broad field that includes the processes of capturing of raw data (in structured, unstructured or semi-structured form), analyzing, and deriving insights from it. It is a multi-disciplinary field that uses mathematical/statistical tools, data analysis, machine learning and and their related methods to manipulate the data so that we can find meaningful information.
Data science is the process of collection of data, analyzing it and making decisions with the help of it. Data scientists create several products and applications based on data and that deals with it. Data science is related to data mining, deep learning (a subset of machine learning) and big data.
In data science, following are the steps:
Step 1: Frame the problem (i.e. asking the correct questions)
Step 2: Collect the raw data needed for problem (i.e. gathering data)
Step 3: Process the data for analysis (i.e. cleaning and transforming the data)
Step 4: Analyze the data (i.e. analyzing data using algorithms and statistical models)
Step 5: Building data visualization (i.e. exploring data by visualizations or graphs)
Step 6: Making predictions (i.e. ML )
Step 7: Recapitulate (i.e. developing more features so as to continuously improve model)
Data mining (DM)
It is a moderately new and multi-disciplinary field of applied computer science. It is the procedure of discovering patterns representing knowledge from large databases by combining methods from artificial intelligence, machine learning and statistics with database management system. The primary goal of data mining is to transform the gathered information or knowledge into a comprehensible form for further use.
Basically, data mining is a subset of data science. It is also considered to be a sub-step in Knowledge discovery in databases (KDD). This topic will be discussed in the next article with necessary details.
Differences between DS and DM
(1) The field of data science concentrates on the scientific study of data, while the field of data mining is mainly concerned with the business process. To be more specific, data science is an area, and data mining is a technique.
(2) Another major difference between DS and DM is that the former is a multi-disciplinary field that consists of mathematics/statistics, social sciences, data visualizations, natural language processing (NLP), data mining etc. while the latter is a subset of the former.
(3) Data science deals with all kinds of data whether structured, unstructured or semi-structured and data mining deals with mostly structured data.
(4) The objective of data science is building predictive models, performing social analysis, revealing unknown facts, and the purpose of data mining is to find new information or pattern only. So, for data science, the output is varied.
(5) Data science aims at building data-centric products for an organization, but data mining aims at making available data more usable.
(6) The term data science has been around since the 1960s, whereas the word data mining became widespread amongst the database communities in the 1990s.
Data Science vs. Data Analytics
Data science is a broad term that covers data analytics, data mining, machine learning, and several other tools/techniques. While a data scientist is expected to forecast the future based on past patterns, data analysts extract meaningful insights from various data sources. A data scientist creates questions, while a data analyst finds answers to the existing set of questions.
Data Engineering vs. Data Science
Data engineering is focused on building infrastructure and architecture for data generation. Data science field, on the other hand, is focused on performing mathematical and statistical analysis on that generated data to forecast the future trends.
Machine learning (ML)
It is an applied field of artificial intelligence (AI) that provides systems the capability to learn and improve automatically from experience without being explicitly programmed. ML mainly concentrates on the development of computer programs that can access data and use it learn for themselves. Of late, the data processing techniques include machine learning based techniques such as association rule mining, cluster analysis, artificial neural network (ANN), decision tree (DT), and support vector machine (SVM) etc.
Basically, data mining uses machine learning based techniques with the intent of revealing hidden patterns in large databases. Thus, the research domain related to data mining reduces the gap between artificial intelligence and applied statistics to database management system by utilizing various data management and data indexing techniques in databases. The goal is to accomplish the actual learning and discovery algorithms more proficiently thereby permitting such approaches to use in larger databases.
Relationships between DS, DM and ML
The figure below shows the relationships between DS, DM and ML.
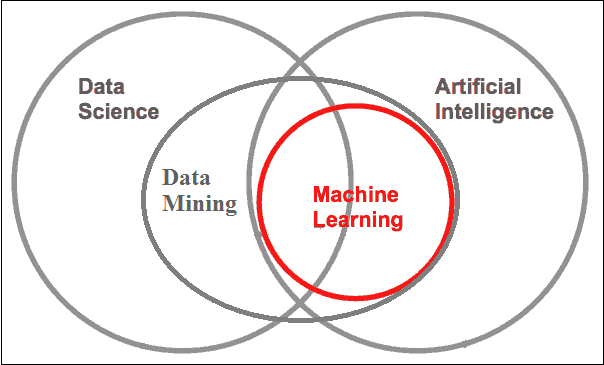
Figure 1: Relationships between DS, DM and ML
Some of the important classification techniques like artificial neural network (ANN), decision tree (DT), support vector machine (SVM) etc. which fall under the area of ML will be discussed here using Python programming language.